What is intelligent document processing (IDP)?
Intelligent document processing (IDP) is a technology that uses artificial intelligence to read, extract, and organize information from documents in any format. It can handle everything from typed forms and emails to handwritten notes and scanned files, turning hard-to-use content into clean, usable data. Some tools that offer these features include ABBYY, Kofax, and Hyperscience.

In the broader landscape of automation, intelligent document processing fits into a group of technologies known as intelligent automation. Intelligent automation brings together artificial intelligence, machine learning, and robotic process automation (RPA) to help businesses complete tasks with less human effort.

The intelligent document processing market is only getting bigger as businesses recognize its benefits, projected to grow at a CAGR of 30.1% between 2025 and 2032.
How does intelligent document processing work?
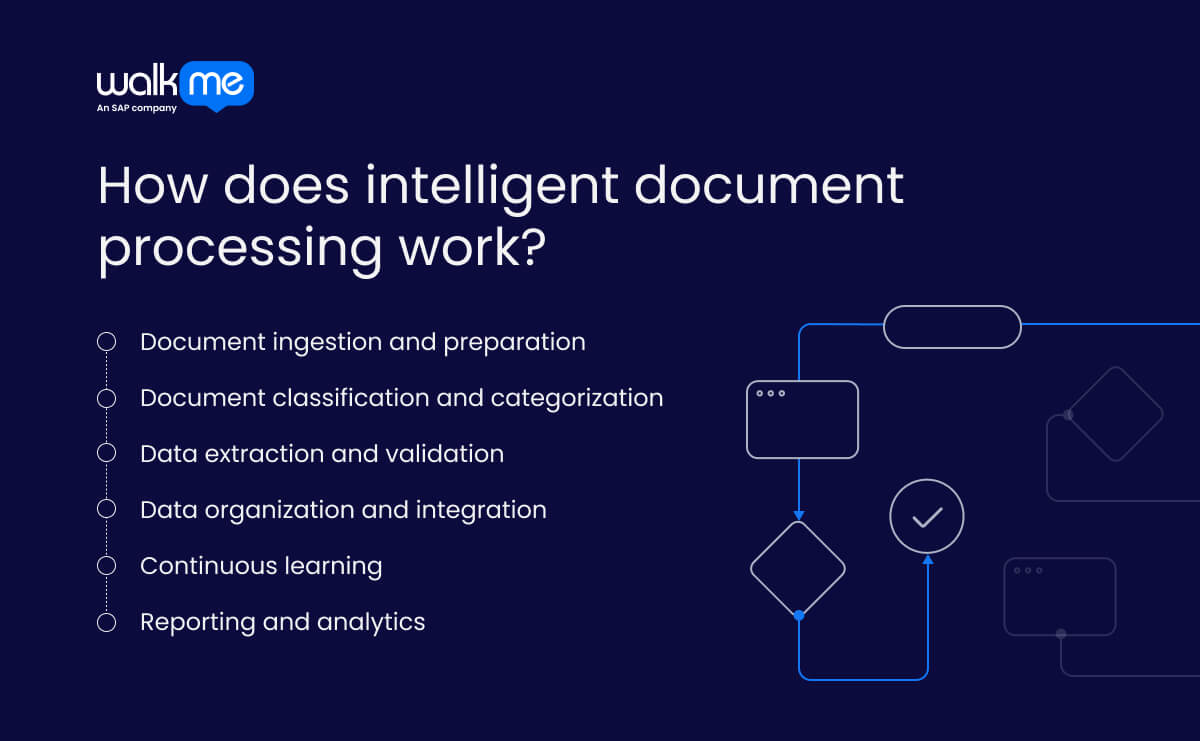
Intelligent document processing turns unstructured information into clear and usable data. The process follows a sequence of steps to collect and understand information before it is moved into business systems for downstream automation or human intervention.
Let’s take a look at how intelligent document processing evaluates data, such as a photo of a receipt or a PDF file with hand-written tables, to deliver structured results that are ready for use.
Document ingestion and preparation
First, the documents need to be collected or ingested. Software will connect to sources such as email inboxes or scanned inputs. It can be triggered manually when someone uploads a file or runs automatically.
Next, the documents are cleaned up to make them more legible in a stage known as preprocessing. Often, ‘noise’ such as wrinkles in scanned paper or watermarks is removed to make extraction easier.
Some key tools used in preprocessing include computer vision, which improves image quality, and Optical Character Recognition (OCR), which turns printed or handwritten words into digital text.
Document classification and categorization
Once the documents have been cleaned up, the system is ready to classify them. For example, files could be invoices, claim forms, or contracts.
The software will not just look at file names or titles to classify documents. Instead, it uses machine learning to look at patterns inside the document, such as certain words or layouts.
Many IDP tools come with pre-trained models that will recognize common document types. In some situations, companies with unique document formats will need to fine-tune the system using internal examples.
Data extraction and validation
The system now recognizes the types of documents it’s working with, allowing it to extract key information during a process known as data extraction. OCR continues to be involved at this stage, gathering any remaining information from the documents.
Working in tandem, natural language processing (NLP) will run, allowing the system to understand the meaning behind what it reads. For example, NLP helps an IDP recognize the difference between a total amount and a tax number, or a date vs a customer ID.
After the correct fields have been identified, the system verifies that the information is accurate during the validation process. It may identify errors such as missing values or incorrect date formats. If this happens, the system can flag it, and a human can intervene.
Data organization and integration
Once the data has been checked and confirmed, the system prepares it for use. The aim is to send the information directly into business tools, in a process called data integration.
First, the system uses natural language processing to understand what each piece of information means. By using NLP, it can handle data that isn’t neatly or clearly structured and match it to the correct fields.
Robotic process automation (RPA) then takes over to move the data into place. It uses clear rules to send information to the relevant parts of other tools a business uses, such as customer databases or billing systems.
Continuous learning
Whenever the system is used, it improves. For example, if someone identifies an error and corrects it, the system will remember those corrections and use them to improve future results.
This is where machine learning makes a big difference. Instead of requiring new, manually written rules to be input, it can proactively learn from real-life examples, such as a wrongly sorted document or a number pulled from the wrong place.
The software, therefore, becomes more accurate and flexible, increasingly capable of dealing with unusual documents.
Reporting and analytics
Once documents are processed, the system reports on what happened. It provides information about the number of documents handled, the time it took to process each one, and whether any issues arose.
Businesses can analyze the effectiveness of the system and gain insight into where improvements might be needed. Furthermore, by tracking reports over time, people can evaluate how accuracy changes over time and whether the system is learning effectively.
Checking that IDP tools are performing accurately and the elements that comprise it, such as NLP and RPA, are maturing and scaling as expected, forms an essential stage in quality assurance. Particularly in regulated industries, maintaining a human-in-the-loop approach is vital, allowing real people to identify errors and maintain high standards.
Intelligent document processing use cases
Intelligent document processing can be transformative in industries that handle large volumes of paperwork. Many sectors now rely on this process to help manage incoming information and improve decision-making.
Finance
In the financial services sector, banks and lenders often rely on processes that involve numerous documents to complete tasks such as verifying customer eligibility for products. They must also have a clear physical or digital workflow to remain compliant. IDP can extract key data from essential files, such as account statements or identity documents, without requiring manual entry. As a result, applications are processed with ease, and the risk of missing important details during compliance checks goes down.
Insurance
Insurance providers regularly receive documents that vary in quality and structure, such as claims and policy forms. With IDP, they can automate the process of identifying documents and extracting relevant fields. They can also be alerted when there are missing files so they can review manually or follow up with the claimant. Claims handlers spend less time on manual document review, and customers benefit from quicker processing times.
Healthcare
In the healthcare sector, numerous documents require regular processing, ranging from handwritten referrals to scanned medical notes that must be uploaded to digital systems. Now that IDP exists, an innovative solution is available that can read and convert the information into structured fields. The output naturally enhances the quality of patient records and reduces administrative workloads, resulting in quicker turnaround times for those requiring medical care.